Sharing the things which I learned about Enterprise Integration.
Search This Blog
The evolution of Distributed Systems
Distributed systems (to be exact, distributed computer systems) has come a long way from where it was started. At the very beginning, one computer could only do one particular task at a time. If we need multiple tasks to be done in parallel, we need to have multiple computers running in parallel. But running them parallel was not enough for building a truly distributed system since it requires a mechanism to communicate between different computers (or programs running on these computers). This requirement of exchanging (sharing) data across multiple computers triggered the idea of the message-oriented communication where two computers share data across using a message which wraps the data. There were few other mechanisms like file sharing, database sharing also came into the picture.
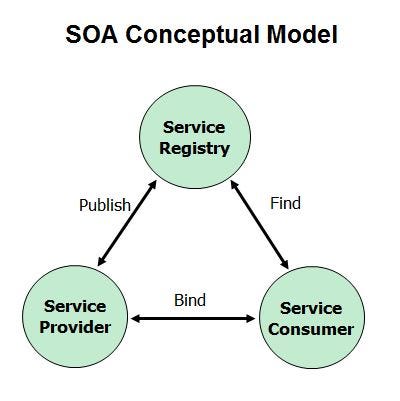
Then came the era of multitasking operating systems and personal computers. With Windows, Unix, Linux operating systems, it was possible to run multiple tasks on the same computer. This allowed distributed systems developers to build and run an entire distributed system within one or few computers which are connected over messaging. This lead to the Service Oriented Architecture (SOA) where each distributed system could be built with integrating a set of services which are running on either one computer or multiple computers. Service interfaces were properly defined through a WSDL (for SOAP) or WADL (for REST) and the service consumers used those interfaces for their client-side implementations.
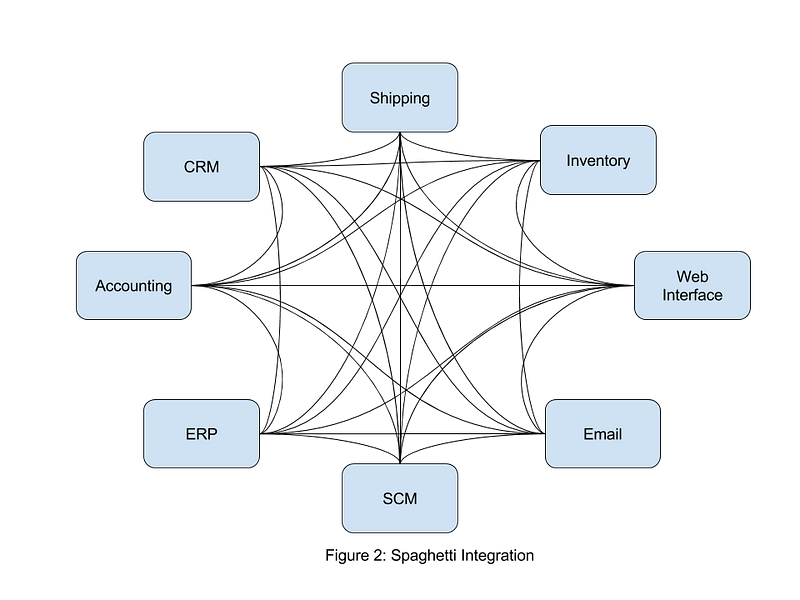
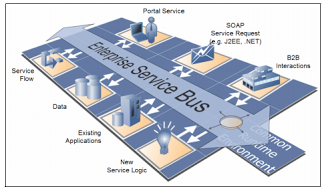
With the reduction of price for computing power and storage, organizations all over the world started using distributed systems and SOA based enterprise IT systems. Once the number of services or systems increased, the point to point connection of these services was no longer scalable and maintainable. This leads to the concept of centralized “Service Bus” which interconnects all different systems via a hub type architecture. This component is called the ESB (Enterprise Service Bus) and it acts as a language translator or a middleman between a set of people who talk different languages but wanted to communicate with each other. In the enterprise, the languages were analogous to messaging protocols and messaging formats which different systems used for their communication. The main advantage of this model was that each system can build server side and client side implementations without worrying about the protocols of the connecting systems.
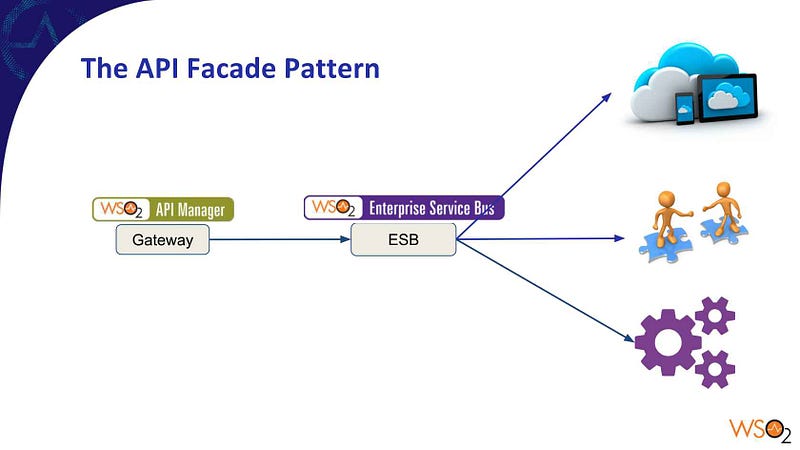
This model was working fine and works fine even today. With the popularity of world wide web and the simplicity of the model, REST-based communication has become more popular than the SOAP-based communication model. This lead to the evolution of Application Programming Interface (API) based communication over REST model. Due to the simplicity of the REST model, the features like security (authentication and authorization), caching, throttling and monitoring type capabilities were needed to implement on top of the standard REST API implementations. Instead of implementing these capabilities at each and every API separately, there came the requirement to have a common component to apply these features on top of the API. This requirement leads the API management platform evolution and today it has become one of the core features of any distributed system.
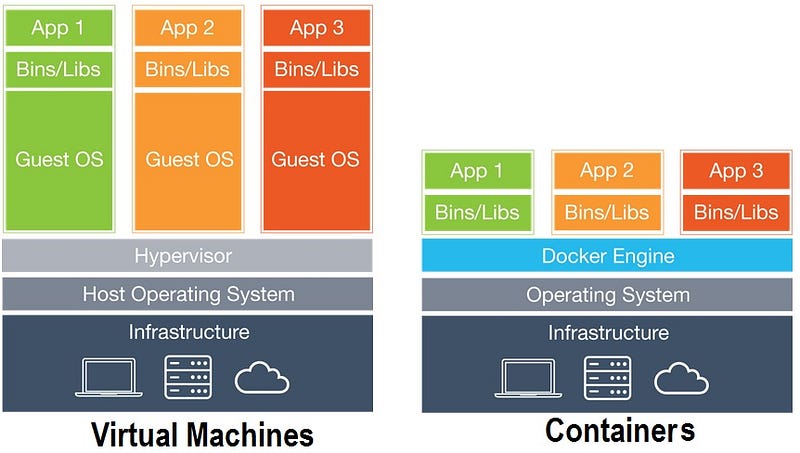
Then came the big bang moment of distributed systems where Internet-based companies like Facebook, Google, Amazon, Netflix, LinkedIn, Twitter became so large that they wanted to build distributed systems which span across multiple geographies and multiple data centres. These types of requirements made the technology focus shift towards the place where it all began. Engineers started thinking about the concept of a single computer and single program. Instead of considering one computer as a one computer, they think about a way to create multiple virtual computers within the same machine. This leads to the idea of virtual machines where same computer can act as multiple computers and run them all in parallel. Even though this was a good enough idea, it was not the best option when it comes to resource utilization of the host computer. Running multiple operating systems required additional resources which was not required when running in the same operating system.
This lead to the idea of containers where running multiple programs and their required dependencies on separate runtime using the same host operating system kernel (Linux). This concept was available with the Linux operating system for some time, it became more popular and improved a lot with the introduction of container-based application deployment. Containers can act as same as virtual machines without having the overhead of a separate operating system. You can put your application and all the relevant dependencies into a container image and that can be run on any environment which has a host operating system which can run containers. Docker and Rocket are 2 popular container building platforms.
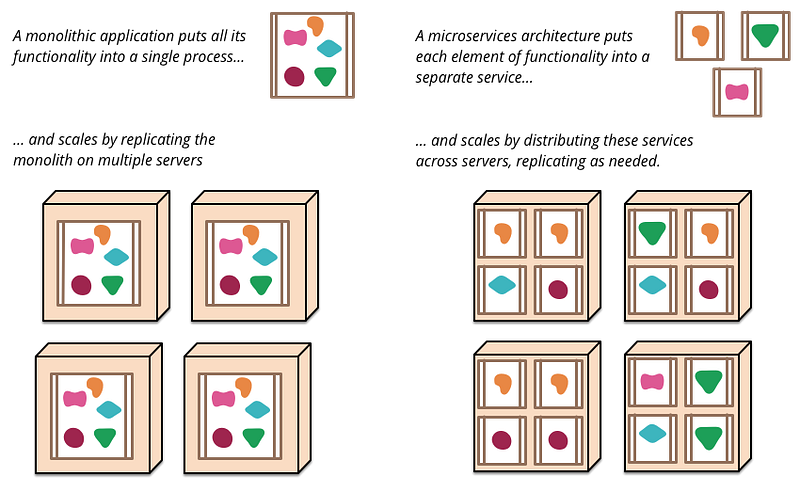
This provided the underlying framework for organizations like Netflix, LinkedIn, Twitter to build their ever demanding always-on multi-region, multi-data-centre application platforms. This didn’t come without complexities though. The miniature nature of the container based deployment brought the complexity of platform maintenance and orchestration across multiple containers. With the invent of microservices architecture (MSA), the monolithic application divided into smaller chunks of microservices which are capable of doing a given functionality of the entire service and deployed in containers (in most cases). This brought a different set of requirements to the distributed systems ecosystem to make the system eventually consistent and communicate with each other without many complexities.
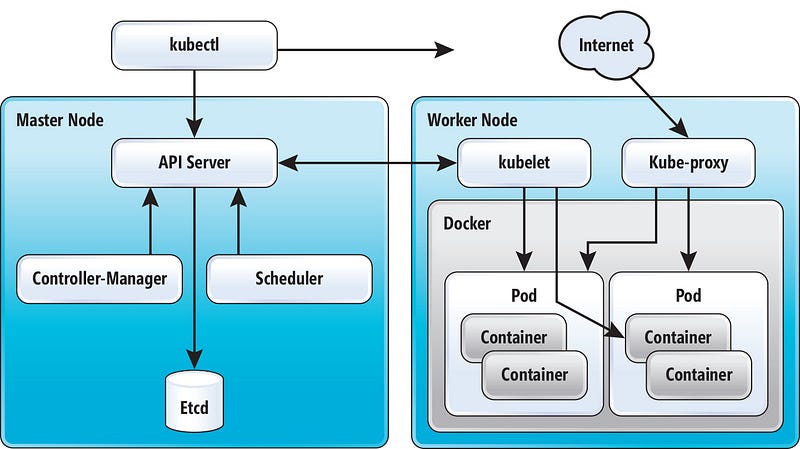
These requirements eventually helped engineers to build a container orchestration system which can be used to maintain the consistency of a larger container-based deployments. There is no surprise that the prominent technology on this domain came from Google given their scale. They built the container orchestration platform called “Kubernetes” (a.k.a k8s) and it became the de-facto standard for large scale container orchestration requirements. K8S allowed engineers to
Run containers in large clusters
Consider the data center as a single computer
Communication between services (which are running on containers)
Automatically scale, load balanced between multiple services
Kubernetes and docker made life easier for application programmers. They no longer wanted to boil their hearts thinking about how it will behave in different environments (operating systems, DEV, TEST, PROD, etc.) since the container image he builds will run almost identical in all the environments given that all dependencies are packaged into it.
But still, with the containers and orchestration frameworks, there should be a team who manages these servers. Meaning that data center needs to be managed using technologies like docker, kubernetes to make sure that it feels like a single computer to the applications. Instead of you doing that, how about someone else manages that part for you. That is exactly what is coming with the serverless architecture where your server will be managed by a 3rd party cloud provider like Amazon (Lambda) , Microsoft (Azure Functions) or Google (Cloud Functions). Now the distributed system will be programmed by application programmers while the underlying infrastructure management will be done by a cloud provider. This is the latest state of the distributed systems evolution and it keeps on evolving.
What are Properties? WSO2 has a huge set of mediators but property mediator is mostly used mediator for writing any proxy service or API. Property mediator is used to store any value or xml fragment temporarily during life cycle of a thread for any service or API. We can compare “Property” mediator with “Variable” in any other traditional programming languages (Like: C, C++, Java, .Net etc). There are few properties those are used/maintained by ESB itself and on the other hand few properties can be defined by users (programmers). In other words, we can say that properties can be define in below 2 categories: ESB Defined Properties User Defined Properties. These properties can be stored/defined in different scopes, like: Transport Synapse or Default Axis2 Registry System Operation Generally, these properties are read by get-properties() function. This function can be invoked with below 2 variations. get-property(String propertyName) get-property(String scop...
I have written several blog posts explaining the internal behavior of the ESB and the threads created inside ESB. With this post, I am talking about the effect of threads in the WSO2 ESB and how to tune up threads for optimal performance. You can refer [1] and [2] to understand the threads created within the ESB. [1] http://soatutorials.blogspot.com/2015/05/understanding-threads-created-in-wso2.html [2] http://wso2.com/library/articles/2012/03/importance-performance-wso2-esb-handles-nonobvious/ Within this blog post, I am discussing about the "worker threads" which are used for processing the data within the WSO2 ESB. There are 2 types of worker threads created when you start sending the requests to the server 1) Server Worker/Client Worker Threads 2) Mediator Worker (Synapse-Worker) Threads Server Worker/Client Worker Threads These set of threads will be used to process all the requests/responses coming to the ESB server. ServerWorker Threads will be used to pr...
In this blog post I am going to describe about how to configure a WSO2 API Manager in a distributed setup with a clustered gateway with WSO2 ELB and the WSO2 G-REG for a distributed deployment in your production environment. Before continuing with this post, you need to download the above mentioned products from the WSO2 website. WSO2 APIM - http://wso2.com/products/api-manager/ WSO2 ELB - http://wso2.com/products/elastic-load-balancer/ Understanding the API Manager architecture API Manager uses the following four main components: Publisher Creates and publishes APIs Store Provides a user interface to search, select, and subscribe to APIs Key Manager Used for authentication, security, and key-related operations Gateway Responsible for securing, protecting, managing, and scaling API calls Here is the deployment diagram that we are going to configure. In this setup, you have 5 APIM nodes with 2 gateway...
Comments
Post a Comment